You've done it. Your Kubernetes cluster is finally production-ready. The applications are deployed, the monitoring is in place, everything is running smoothly. But what happens when disaster strikes? Maybe a server goes down, or the cloud provider has an outage. Without a solid disaster recovery plan, your cluster could be left inoperable.
Don't let that happen to you! In this guide, we'll walk you through Kubernetes disaster recovery from start to finish. You'll learn best practices for backup and restore, multi-cluster redundancy, and more. We've made plenty of mistakes so you don't have to.
Follow along as we show you how to prepare for the worst so you can keep your cluster up and running no matter what life throws at it. With the right strategy, you can master Kubernetes disaster recovery.
Understanding Disaster Recovery for Kubernetes
When managing Kubernetes, preparing for potential disasters is critical. Disaster recovery (DR) ensures your cluster can withstand events like network outages, power failures, or natural disasters and continue operating.
Have a Backup Strategy
The most important part of DR is backing up your data. Regularly backup Kubernetes objects like Deployments, Pods, Services, and PersistentVolumes. You'll also want to backup namespace and RBAC objects. Store backups in a separate location from your cluster.
Plan for Cluster Failure
Even with backups, there's still a chance your entire cluster could become unavailable. Prepare by running Kubernetes clusters in multiple availability zones. That way, if one zone goes down, the other will continue working. You can also replicate clusters in entirely separate regions.
Prepare for Network Interruptions
Network failures happen, so have a plan to handle them. Use a service like Kubernetes Federation to sync resources across clusters in multiple regions. This ensures that even if the network between regions is disrupted, each region can continue operating independently. You'll also want redundant network paths, load balancers, and DNS services.
Practice and Test Regularly
The only way to know if your DR plan will work is to practice it. Run simulations of disasters and network interruptions to test how your cluster responds. Check that backups are functioning properly and data is recoverable. Look for any bottlenecks or single points of failure. Update your
DR plan based on the results.
Disaster recovery is an ongoing process. As your infrastructure and application needs change, revisit your DR plan and processes. Regular testing and practice will give you confidence your Kubernetes cluster can withstand any interruption and continue serving your applications. With some preparation, disaster recovery doesn't have to be so disastrous.
Best Practices for Kubernetes Cluster Backup
Have a Backup Strategy In Place A solid backup strategy is essential to any disaster recovery plan. For your Kubernetes cluster, you'll want to backup both the control plane as well as the worker nodes. The control plane contains critical components like the API server, scheduler, and controller manager. Losing this data could mean losing your entire cluster. Worker nodes contain your applications and data. You'll want to backup both the node configuration as well as the persistent volumes attached to your workloads.
Backup Kubernetes Control Plane Components
The control plane components are typically single points of failure, so backing them up is critical. You have a few options here:
Take periodic etcd snapshots. Etcd is the datastore for Kubernetes, so backing it up gives you a snapshot of your cluster at that point in time.
Backup Worker Nodes
Your worker nodes contain your applications and data, so you'll want to backup a few things:
The node configuration (files in /etc) to rebuild worker nodes if needed.
Test Your Backups Regularly
The only way to know if your Kubernetes backup strategy will work in a disaster scenario is to test it. Regularly test restoring backups to ensure:
Backups are valid and not corrupt. Testing backups is the only way to identify issues before an actual disaster strikes. Make backup testing a regular part of your Kubernetes disaster recovery plan.
Kubernetes Disaster Recovery Strategies
Back up your cluster configuration the configuration of your Kubernetes cluster contains critical information to recreate your cluster in case of a disaster. Back up YAML files for namespaces, deployments, services, ingress, and storage classes. Store copies of these files in a git repository, and back up the repository regularly.
Use persistent storage
Any stateful workloads in your cluster, like databases, will lose data if the underlying nodes fail. Provision persistent storage that is external to your cluster, such as network attached storage, storage area networks, or cloud-based storage services. Configure your stateful workloads to use this external storage to persist data.
Enable clustering logging
Enable logging for all components in your Kubernetes cluster, including the control plane and worker nodes. Aggregate logs in a centralized logging system outside your cluster. Logs contain important troubleshooting information in case of issues and can help determine the root cause of cluster failure.
Use a container registry
Have a container registry, like Docker Hub, Google Container Registry or Azure Container Registry, to store container images for your Kubernetes deployments. In case you need to rebuild your cluster, you can redeploy applications from these images. Build a CI/CD pipeline to automatically push updated images to your registry.
Choose a disaster recovery solution
There are a few options for disaster recovery with Kubernetes, including:
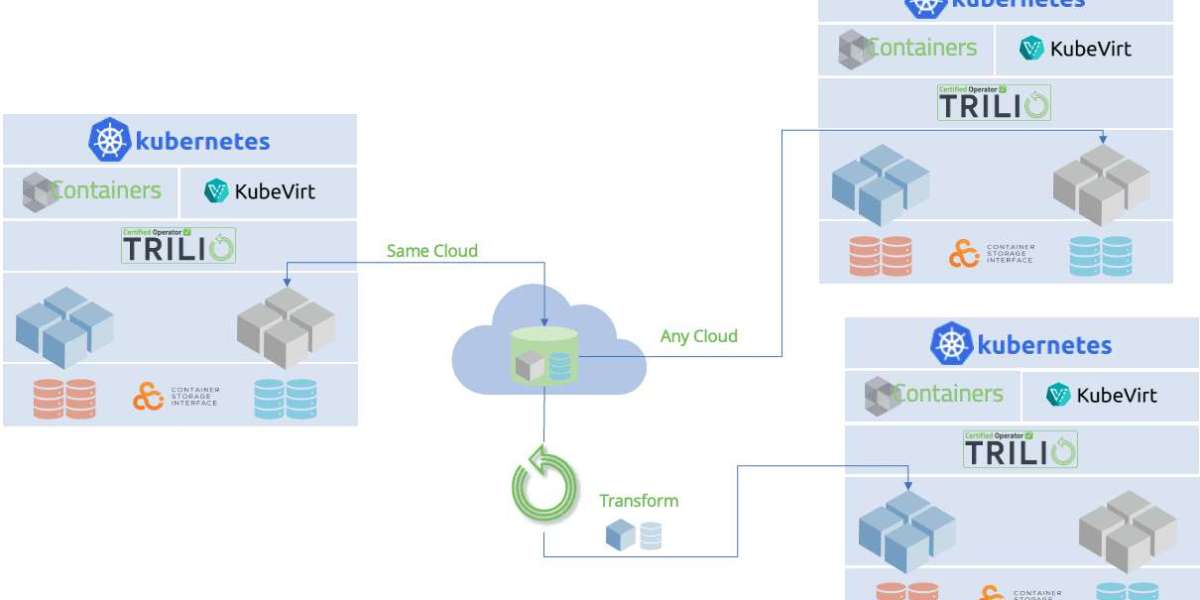
Backup and restore - Take periodic backups of your cluster and restore from backup in case of failure. Multiple clusters - Deploy the same Kubernetes cluster in multiple regions or zones. Keep configurations in sync between clusters. In a disaster scenario, direct traffic to an available cluster. Migration tools - Use tools like Velero or Kubermatic Kubernetes Platform to migrate cluster resources between clusters. Set up scheduled syncs between clusters.
Planning and preparing for disaster recovery will help ensure your Kubernetes cluster is resilient. With the proper strategies in place, you can recover quickly from failures and minimize downtime. Staying on top of Kubernetes best practices around high availability and redundancy will also help avoid disasters in the first place.








